
Per chi si occupa di SEO il termine può essere familiare, ma approfondendo l’argomento ci accorgiamo che anche sui siti dei cosiddetti guru della SEO c’è molta confusione. Cerchiamo pertanto di capire cos’è il crawl budget e cerchiamo soprattutto di capire come usare questo parametro in ottica SEO.
In questo articolo, cerchiamo quindi di chiarire meglio come lavora Googlebot è perché il crawl budget di potrebbe essere importante per il posizionamento del tuo sito web.
Cos’è il Crawl Budget di Googlebot
La definizione che viene data comunemente del crawl budget è il numero di pagine che Google sottopone a scansione in un determinato periodo di tempo.
Tuttavia approfondendo l’argomento, sul sito di Google si legge che il termine “crawl budget” non corrisponde esattamente ad un valore ma è un parametro che rappresenta l’insieme di due valori, vale a dire il Crawl rate limit (limite di scansione) e il Crawl Domand (richiesta di scansione), ossia indica:
La richiesta di accedere ad un set di pagine ed i limiti che lo spider di Google incontra ad effettuare effettivamente questa scansione.
Approfondiamo meglio questi due argomenti per entrare più nel dettaglio e capire come lavora il Bot di Google e perchè il crawl budget è importante.
Cos’è il Crawl rate limit (limite di scansione)
Googlebot è progettato per leggere e scansionare miliardi di pagine ogni giorno e può accedere molte volte al vostro sito nella stessa giornata. Immaginiamo un sito di migliaia di pagine. Il Googlebot, nel tentativo di leggere tutte le pagine e mantenere aggiornato il proprio indice, potrebbe quindi generare un volume notevole di traffico e pesare sul sito. In effetti il traffico di Google su un sito potrebbe pesare proprio come quello di un utente che accede continuamente a tutte le pagine del sito su base regolare.
Nel allocare le proprie risorse (capacità di scansione) Google vuole essere che queste scansioni ripetute ed approfondite non impattino negativamente sul sito pertanto imposta “limite della velocità di scansione”, ossia un limite alla velocità di recupero per un determinato sito.
Quindi il Crawl rate limit è il numero di connessioni parallele simultanee che Googlebot può utilizzare per eseguire la scansione del sito. La velocità di scansione può aumentare o diminuire in base a un paio di fattori:
- Fattori interni o strutturali: il sito è lento, contiene errori, pagine inesistenti, etc. allora il Googlebot rallenta la sua velocità di scansione.
- Impostazione della Google Search Console: è possibile limitare manualmente il valore di questo dato tramite la Google Search Console, limitando quindi volontariamente l’impatto del traffico generato da Google.
Cos’è la Crawl demand (richiesta di scansione)
Questa parametro indica quanto il sito sia ‘meritorio’ di essere scansionato.
I fattori che incidono sulla domanda di crawling (scansione) sono diversi ma sostanzialmente sono di due tipi:
- Popolarità: gli URL che sono più popolari tendono a essere sottoposti a scansione più spesso;
- Obsolescenza / errori: pagine vecchie, poco aggiornate, contenenti errori e con metriche basse, tendono ad essere scansionate meno spesso.
In sostanza quindi budget di scansione (crawl budget) è un parametro che riassume questi due valori.
Il Crawl Budget è importante?
Anche su questo punto Google è molto chiaro. Per la maggior parte di siti web con un numero basso di pagine (meno di un migliaio) ed aggiornamenti relativamente poco frequenti (ad esempio un blog, siti istituzionali, landing page, siti vetrina, etc.) questo parametro non ha alcuna influenza, in quanto Google non ha alcun problema a scansionare il sito.
Si legge infatti su Google:
Innanzitutto, vorremmo sottolineare che il budget per la scansione non è qualcosa di cui la maggior parte dei siti devono preoccuparsi. […] se un sito ha meno di qualche migliaio di URL, il più delle volte verrà sottoposto a scansione in modo efficiente.
Lo stesso John Muller sul suo canale indica che il fattore crawl-budget è generalmente sopravvalutato e molti webmaster non hanno ragione di preoccuparsene.

Come determinare il crawl budget del tuo sito
Per determinare il crawl budget del tuo sito occorre utilizzare la Google Search Console del tuo sito ed accedere alla sezione statistiche di scansione, come mostrato nell’immagine seguente.
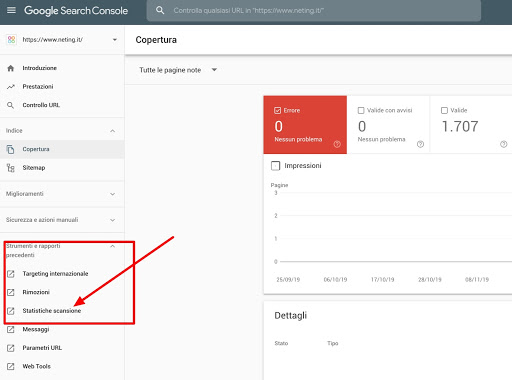
Accedendo a questa pagina si trovano appunto le statistiche di accesso al nostro sito da parte dello spider di Google, il famoso Googlebot:
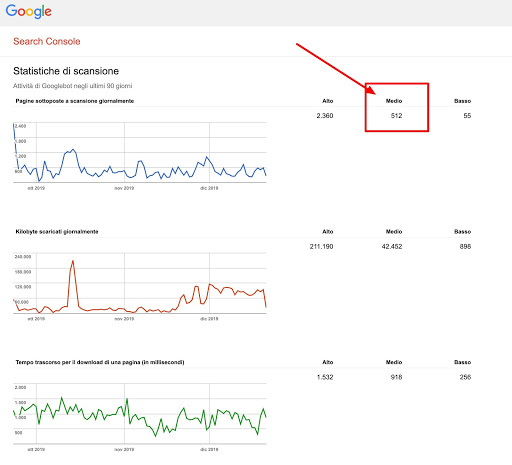
Dal rapporto descritto sopra, possiamo vedere che in media Google esegue ogni giorno la scansione di 512 pagine del nostro sito. Da ciò, posso capire che il mio budget di ricerca per indicizzazione mensile è 512 * 30 = 15.360.
La velocità di scansione può essere soggetta a cambiamenti e fluttuazioni ma questo numero da una idea di quante pagine del tuo sito puoi aspettarti di sottoporre a scansione in un determinato periodo di tempo.
Se hai bisogno di una analisi più dettagliata (ad esempio quante volte il Google bot accede ad una specifica pagina) il passo successivo è dare una letta ai log del tuo server.
Il percorso dei file di registro dipende dalla configurazione del server.
Apache, in genere, mantiene dei log di accesso di questo tipo:
- /var/log/httpd-access.log
- /var/log/httpd/access_log
- /var/log/apache2/access.log
Per maggiori dettagli comunque vi consiglio di rivolgervi al vostro amministratore del server.
Capire se il tuo sito ha un problema di Crawl Budget
Una volta determinato il crawl budget del sito, ossia quanto lavoro fa il bot di Google sul nostro sito e con quanta frequenza ci visita, cerchiamo di capire se il sito ha effettivamente un problema di scansione e quindi di crawl budget.
Per determinare rapidamente se il tuo sito presenta un problema di budget per la scansione, procedi nel seguente modo:
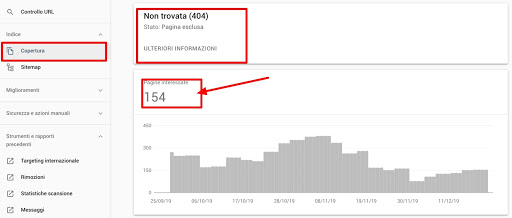
- determina il numero di pagine inviate in sitemap (ad esempio per il nostro sito sono circa 650 pagine in sitemap)
- determina il numero di URL scansionati giornalmente (come abbiamo visto prima nel nostro caso è di circa 512 pagine / giorno)
- dividi il numero di pagine in sitemap per il valore di pagine scansionate, nel nostro caso viene 1.25. Con questo parametro abbiamo quindi un valore che ci dice ogni quanti giorni il bot di Google ritorna mediamente a visitare la stessa pagina.
- se il valore è alto (>5), potresti avere un problema di scansione!
Nel nostro caso abbiamo visto che in effetti il crawler di Google riesce mediamente a scansionare tutto il sito in un paio di giorni al massimo, quindi non si rileva in particolare alcuna criticità.
Cosa diversa potrebbe essere il fatto di avere un valore di > 10, questo vorrebbe dire che mediamente ogni nuova pagina (o modifica) del sito potrebbe richiedere fino a 10 giorni per essere rilevata.
Fattori che influenzano il Crawl Budget
Gli errori che incidono negativamente sulla scansione del sito e quindi sul Crawl Budget sono sostanzialmente del seguente tipo:
Hacked pagine
Inutile dire che siti web che contengono contenuti hackerati e possibili minacce per la sicurezza degli utenti sono ovviamente penalizzate e Google non desidera perdere tempo a scansionare ed indicizzare queste pagine. Consigliamo sempre di aggiornare i siti web mantenendo i CMS e relativi plugins sempre up-to-date!
Infinite spaces e proxies
Quando Googlebot esegue la scansione del Web, trova spesso quello che viene solitamente chiamato come uno “spazio infinito”. Si tratta di un numero molto elevato di collegamenti che di solito forniscono pochi o nessun nuovo contenuto per l’indicizzazione di Googlebot. Se ciò accade sul tuo sito, la scansione di tali URL potrebbe utilizzare una larghezza di banda non necessaria e potrebbe impedire a Googlebot di indicizzare completamente il contenuto reale sul tuo sito, sprecando risorse per contenuti a basso valore aggiunto.
Il classico esempio di “spazio infinito” è un calendario con i link ai mesi successivi. Googlebot potrebbe continuare a seguire per sempre quei link del “Mese prossimo” raggiungendo comunque pagine di poco valore e contenuto.
Un altro scenario comune è rappresentato dai filtri presenti nei siti Web di ecommerce che consentono di visualizzare gli stessi prodotti in molti modi. Un sito di abbigliamento online potrebbe consentire di selezionare e filtrare i capi di vestiario per categoria, prezzo, colore, marca, stile, ecc. Il numero di possibili combinazioni di filtri può aumentare in modo esponenziale. L’utilizzo di filtri che creano pagine dinamiche in questo modo può produrre migliaia di URL, tutti in grado di trovare un sottoinsieme degli articoli venduti. Questo può essere conveniente per i tuoi utenti, ma non è così utile per Googlebot, che vuole solo trovare tutto – una volta!
Contenuti di bassa qualità e con link spam
Sprecare risorse del server su pagine come queste distoglierà l’attenzione del crawler da pagine che hanno effettivamente un valore, il che potrebbe causare un ritardo significativo nella scoperta dei contenuti che hanno realmente un valore e che sono aggiornati con maggiore frequenza.
Inoltre siti che presentano pagine con link a contenuti a loro volta di bassa qualità o a siti di spam può segnalare a Google che il contenuto è poco meritevole di attenzione.
Parametri di navigazione ed identificativi di sessione
L’uso dei parametri nell’URL (querystring) come il filtro per colore o fascia di prezzo, può essere utile per filtrare i risultati di ricerca ma spesso crea molte combinazioni di URL con contenuti duplicati. Con URL duplicati, i motori di ricerca potrebbero non eseguire la scansione di contenuti unici nuovi o aggiornati con la stessa rapidità e/o potrebbero non indicizzare una pagina in modo accurato poiché i segnali di indicizzazione sono diluiti tra le versioni duplicate.
Contenuti duplicati
Pagine che contengono informazioni e contenuti simili diluiscono l’authority del contenuto e possono ridurre l’interesse dello spider di Google per i nostri contenuti. Evitare di richiedere l’indicizzazione di contenuti duplicati o creare siti (o pagine) che sono la copia di altre.
Errori soft di scansione (soft 404)
Capire cosa è un errore soft 404 può essere un po’ tricky. Secondo Google infatti è
Un errore soft 404 indica un URL che restituisce una pagina in cui viene comunicato all’utente che la pagina non esiste e in cui viene indicato anche un codice 200 (OK). In alcuni casi si tratta di una pagina con contenuti esigui o senza contenuti, ad esempio una pagina vuota o con contenuti sparsi.
Fondamentalmente, hai una pagina sul tuo sito che dice ai visitatori che non esiste più, ma allo stesso tempo, sta dicendo ai motori di ricerca che esiste.
Abbastanza confusionario, vero?
In sostanza è una pagina che ritorna un codice di pagina OK (ossia un 200) ma che in sostanza comunica che la pagina non è stata trovata. E’ la classica pagina che troviamo in un sito quando cerchiamo di accedere ad una pagina non esistente. Tuttavia se una pagina non esiste, il codice corretto da restituire a Google dovrebbe essere 404.
In alcuni casi, potrebbe trattarsi di una pagina del tuo sito che non presenta molti contenuti. Ad esempio, WordPress genera automaticamente un nuovo URL quando crei un nuovo tag per il tuo sito. Se hai creato un tag ma non hai ancora pubblicato alcun post utilizzando il tag, avrai una pagina vuota sul tuo sito e potenzialmente un errore soft 404.
Quindi come interpreta Google queste pagine? Quando esegue la scansione del tuo sito e si imbatte in una pagina che il server afferma che esiste (ossia restituisce un codice 200) ma il contenuto suggerisce il contrario, Google pensa “bene, questa pagina non offre alcun valore agli utenti, quindi non vale la pena indicizzarla” e gli conferisce un’etichetta soft 404.
La velocità del sito ha un impatto positivo sul Crawl Budget
Per Googlebot un sito veloce è un segnale di un sito web sano su server integri, quindi può ottenere più contenuti sullo stesso numero di connessioni quindi in sostanza, rendere un sito web più veloce non solo migliora l’esperienza degli utenti ma aumenta anche la velocità di scansione.
Si consiglia di prestare sempre attenzione alla velocità del sito, anche grazie al nuovo report che è stato inserito nella Search Console di Google.
Il Crawl Budget è un fattore di posizionamento di cui tenere conto
Ecco infine le domanda che tutti si pongono. Avere un ottimo crawl budget porta a posizionamenti migliori in SERP? Anche su questo Google è abbastanza perentorio, rispondendo a questa domanda con la seguente frase:
Un aumento della velocità di scansione non porterà necessariamente a migliori posizioni nei risultati di ricerca. Google utilizza centinaia di segnali per classificare i risultati e mentre la ricerca per indicizzazione è necessaria per essere nei risultati, non è un segnale di classifica.
Da parte nostra possiamo dire che un sito web veloce ha comunque sempre risultati migliori in termini di posizionamento, questo soprattutto grazie alla migliore esperienza degli utenti.
Inoltre questo è un fattore determinante per il posizionamento da mobile, sempre più importante.
Conclusioni
Da questa veloce analisi abbiamo capito che il Googlebot Crawl Budget non è un fattore particolarmente critico per piccoli siti web (<1000 pagine) ma può diventare particolarmente critico per siti di grandi dimensioni con contenuti particolarmente dinamici (ad esempio, ecommerce, siti di notizie, siti con molti contenuti aggiornati spesso . – esempio previsioni meteo, aggregatori di notizie, marketplace, etc.).
Il crawl budget di per sé non è un fattore di posizionamento ma una misura dello stato di salute del sito. Pertanto l’attenzione che Google riserva al nostro sito web è un indice di quanto il nostro sito sia meritorio.
Il consiglio che possiamo darvi è di prestare sempre molta attenzione alla console di Google Search, strumento che contiene molti elementi importanti di valutazione. Se il vostro sito è particolarmente importante per la vostra attività o avete come obiettivo di farlo crescere dovreste cercare di capire come Googlebot lo scansiona e quale è l’effettivo stato di salute.
Infine, visto che stiamo parlando di argomenti particolarmente tecnici, non tanto per la valutazione di merito che può essere fatta con gli strumenti indicati, ma per apportare soluzioni e modifiche tecniche per migliorare i risultati, vi consigliamo di fare sempre riferimento ad un professionista SEO per la valutazione dello stato del vostro sito e per implementare modifiche o strategie che possono incidere con sulle scansioni dello stesso da parte di Google.